
Michael Auli
Principal Research Scientist/Director
Facebook AI Research
Menlo Park, CA
1st.last@gmail.com
 Google Scholar
Google Scholar
 LinkedIn profile
LinkedIn profile
 Twitter
Twitter
Facebook AI Research
Menlo Park, CA
1st.last@gmail.com
I am a Principal Research Scientist/Director at Meta/FAIR in Menlo Park where I work on machine learning, speech processing and NLP which resulted in projects such as wav2vec, the fairseq toolkit, the first modern convolutional seq2seq models outperforming RNNs, as well as top ranked submissions at the WMT news translation task in 2018 and 2019. Before that I was at Microsoft Research, where I did early work on neural machine translation and neural dialogue models. I earned my Ph.D. at the University of Edinburgh where I was advised by Adam Lopez and Philipp Koehn.
News
- MMS scales speech technology to 1,000+ languages and provides language identification for over 4,000 languages.
- data2vec 2.0 enables pre-training for speech, vision and NLP at up to 16x the speed of existing algorithms.
- We released data2vec, a single self-supervised learning algorithm which achieves high peformance for vision, speech and language.
Selected Papers (See Google Scholar for full list)

Scaling Speech Technology to 1,000+ Languages
Vineel Pratap, Andros Tjandra, Bowen Shi, Paden Tomasello, Arun Babu, Sayani Kundu, Ali Elkahky, Zhaoheng Ni, Apoorv Vyas, Maryam Fazel-Zarandi, Alexei Baevski, Yossi Adi, Xiaohui Zhang, Wei-Ning Hsu, Alexis Conneau, Michael Auli. In JMLR, 2024.
Abstract Blog Code
Vineel Pratap, Andros Tjandra, Bowen Shi, Paden Tomasello, Arun Babu, Sayani Kundu, Ali Elkahky, Zhaoheng Ni, Apoorv Vyas, Maryam Fazel-Zarandi, Alexei Baevski, Yossi Adi, Xiaohui Zhang, Wei-Ning Hsu, Alexis Conneau, Michael Auli. In JMLR, 2024.
Abstract Blog Code

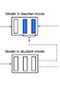
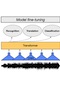
XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale
Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli. In arXiv, 2021.
Abstract Blog Code
Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli. In arXiv, 2021.
Abstract Blog Code


Beyond english-centric multilingual machine translation
Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli*, Armand Joulin*. In JMLR, 2020.
Abstract Blog Code
Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli*, Armand Joulin*. In JMLR, 2020.
Abstract Blog Code





Press
Meta researchers build an AI that learns equally well from visual, written or spoken materials TechCrunch, 20 Jan 2022.
Meta’s new learning algorithm can teach AI to multi-task MIT Technology Review, 20 Jan 2022.
Facebook Wav2vec-U learns to recognize speech from unlabeled data Venturebeat, 21 May 2021.
Facebook claims wav2vec 2.0 tops speech recognition performance with 10 minutes of labeled data Venturebeat, 23 June 2020.
Facebook details wav2vec, an AI algorithm that uses raw audio to improve speech recognition. Venturebeat, 5 Nov 2019.
Facebook's new AI could lead to translations that actually make sense. Wired, 9 May 2017.
Talks

Unified self-supervised learning for speech, vision and NLP
Talk at ECCV Workshop on Perception
Talk at ECCV Workshop on Perception

wav2vec: Self-supervised learning of speech representations
Talk at MIT, CMU, U of Edinburgh, Spring 2021.
Talk at MIT, CMU, U of Edinburgh, Spring 2021.

Efficient Sequence Modeling
Talk at WNGT'19, Stanford, Berkeley, Nov 2019.
Talk at WNGT'19, Stanford, Berkeley, Nov 2019.
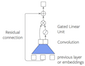
Sequence to Sequence Learning: Fast Training and Inference with Gated Convolutions
Talk at Johns Hopkins University, Oct 2017.
Talk at Johns Hopkins University, Oct 2017.
Learning to translate with neural networks
Talk at Facebook, Google, Amazon and the University of Washington, 2014.
Talk at Facebook, Google, Amazon and the University of Washington, 2014.

Integrated Parsing and Tagging
Talk at Carnegie Mellon University, Johns Hopkins University, BBN Technologies, IBM Research and Microsoft Research, 2011.
Talk at Carnegie Mellon University, Johns Hopkins University, BBN Technologies, IBM Research and Microsoft Research, 2011.